Transformer Model – หัวใจ AI ยุคใหม่ในเทคโนโลยีสารสนเทศ
ในช่วงทศวรรษที่ผ่านมา เทคโนโลยีสารสนเทศ (Information Technology) ได้ก้าวเข้าสู่ยุคใหม่ที่ปัญญาประดิษฐ์ (Artificial Intelligence: AI) กลายเป็นศูนย์กลางของการเปลี่ยนแปลง ไม่ว่าจะเป็นด้านธุรกิจ การศึกษา การแพทย์ หรือความบันเทิง AI ได้เข้ามาช่วยเพิ่มประสิทธิภาพและสร้างมูลค่าอย่างมหาศาล หนึ่งในนวัตกรรมที่ถือเป็นจุดเปลี่ยนครั้งใหญ่ของวงการคือ Transformer Model ซึ่งถูกนำเสนอโดยทีมวิจัยของ Google Brain และ Google Research ในปี 2017 ผ่านงานวิจัยชื่อ “Attention Is All You Need”
การปรากฏตัวของ Transformer Model ไม่เพียงแต่แก้ปัญหาข้อจำกัดของโมเดลก่อนหน้าอย่าง RNN และ LSTM แต่ยังกลายเป็นรากฐานของโมเดลภาษาขนาดใหญ่ (Large Language Model: LLM) ที่เราคุ้นเคยในปัจจุบัน เช่น GPT, BERT, T5, และ PaLM บทความนี้จะพาคุณไปทำความเข้าใจ Transformer Model ในทุกมิติ ทั้งแนวคิด กลไก จุดเด่น การใช้งาน และอนาคต เพื่อให้เห็นว่าทำไมมันถึงสำคัญต่อโลกเทคโนโลยีสารสนเทศอย่างยิ่ง
Transformer Model คืออะไร?

Transformer Model คือสถาปัตยกรรมโครงข่ายประสาทเทียม (Neural Network Architecture) ที่ถูกออกแบบมาเพื่อประมวลผลข้อมูลที่มีลำดับ (sequential data) เช่น ข้อความ เสียง หรือแม้กระทั่งภาพ จุดเด่นหลักของโมเดลนี้คือการใช้ Attention Mechanism โดยเฉพาะ Self-Attention แทนการประมวลผลแบบลำดับทีละขั้นเหมือน RNN หรือ LSTM
สิ่งนี้ช่วยให้ Transformer สามารถเข้าใจความสัมพันธ์ระหว่างองค์ประกอบต่าง ๆ ในข้อมูลได้อย่างแม่นยำ ยกตัวอย่างเช่น เมื่ออ่านประโยค “แมววิ่งไล่จับหนูเพราะมันหิว” คำว่า “มัน” ในที่นี้ควรเชื่อมโยงกับ “แมว” ไม่ใช่ “หนู” กลไก Self-Attention ทำให้โมเดลเข้าใจความสัมพันธ์นี้ได้ดีกว่าโมเดลก่อนหน้า
ข้อดีของ Transformer Model:
- ประมวลผลแบบขนาน (Parallel Processing): ต่างจาก RNN ที่ต้องอ่านข้อมูลทีละคำ Transformer สามารถประมวลผลข้อมูลทั้งหมดพร้อมกัน ทำให้ฝึกสอนได้เร็วขึ้นมาก
- รองรับข้อมูลขนาดใหญ่ (Scalability): สามารถขยายขนาดโมเดลได้อย่างมีประสิทธิภาพ ซึ่งเป็นพื้นฐานของโมเดล AI ขนาดยักษ์ในปัจจุบัน
- ความแม่นยำสูง: กลไก Attention ทำให้เข้าใจความสัมพันธ์เชิงซับซ้อนของคำได้ดีกว่าเดิม
- ความยืดหยุ่นในการใช้งาน: Transformer ไม่ได้จำกัดแค่ข้อความ แต่สามารถนำไปใช้กับภาพ เสียง วิดีโอ และแม้แต่การวิเคราะห์โครงสร้างโปรตีน
องค์ประกอบสำคัญของ Transformer Model
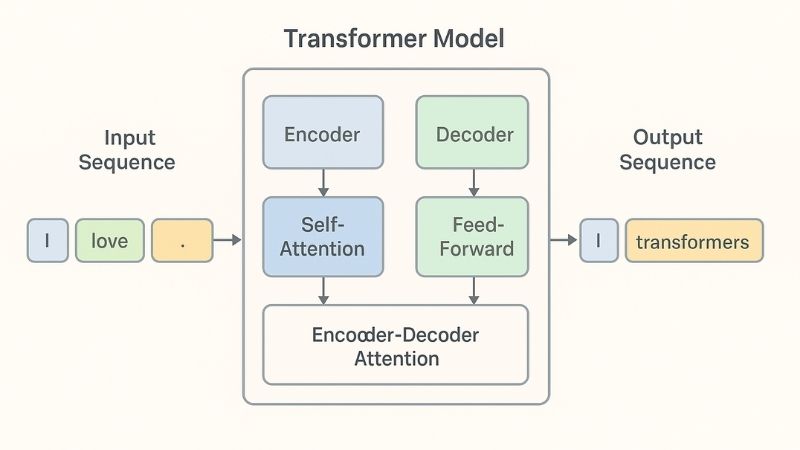
การทำงานของ Transformer Model นั้นซับซ้อนแต่ทรงพลัง เพราะถูกออกแบบมาด้วยกลไกเฉพาะที่ช่วยให้สามารถประมวลผลข้อมูลลำดับได้อย่างมีประสิทธิภาพ องค์ประกอบแต่ละส่วนทำงานประสานกันจนกลายเป็นหัวใจสำคัญของโมเดล ไม่ว่าจะเป็น Encoder, Decoder, Self-Attention หรือ Position Encoding ล้วนมีบทบาทสำคัญในการทำให้โมเดลนี้เหนือกว่าโครงสร้างแบบเดิม
– Encoder และ Decoder
- Encoder: ทำหน้าที่รับอินพุต (เช่น ข้อความภาษาไทย) และเข้ารหัสข้อมูลเป็นเวกเตอร์เชิงความหมาย
- Decoder: แปลงเวกเตอร์ที่ได้ออกมาเป็นเอาต์พุต (เช่น ข้อความภาษาอังกฤษในงานแปลภาษา)
– Self-Attention
คือหัวใจสำคัญของ Transformer ทำให้โมเดล “เลือก” ข้อมูลที่เกี่ยวข้องได้อย่างชาญฉลาด ตัวอย่างเช่น คำว่า “bank” อาจหมายถึง “ธนาคาร” หรือ “ริมฝั่งแม่น้ำ” กลไก Self-Attention จะช่วยตีความตามบริบทของประโยค
– Multi-Head Attention
แทนที่จะโฟกัสเพียงมุมมองเดียว Multi-Head Attention ช่วยให้โมเดลมองเห็นความสัมพันธ์หลายมิติในเวลาเดียวกัน
– Position Encoding
เนื่องจาก Transformer ไม่อ่านข้อมูลตามลำดับแบบ RNN จึงต้องมีการเข้ารหัสตำแหน่ง (Position Encoding) เพื่อให้โมเดลเข้าใจว่า “ลำดับของคำ” มีความหมาย
การประยุกต์ใช้ Transformer Model ในเทคโนโลยีสารสนเทศ

Transformer Model ไม่ได้เป็นเพียงแนวคิดทางวิชาการ แต่ได้ก้าวเข้าสู่การใช้งานจริงในหลากหลายด้านของเทคโนโลยีสารสนเทศ ความสามารถในการประมวลผลข้อมูลเชิงลำดับและทำความเข้าใจบริบทอย่างลึกซึ้ง ทำให้โมเดลนี้ถูกนำไปต่อยอดในงานต่าง ๆ ไม่ว่าจะเป็นระบบประมวลผลภาษาธรรมชาติ การค้นหาข้อมูลอัจฉริยะ การวิเคราะห์ภาพและเสียง ไปจนถึงการแพทย์และธุรกิจยุคดิจิทัล
การประมวลผลภาษาธรรมชาติ (NLP)
การแปลภาษา (Machine Translation) เช่น Google Translate ที่มีความแม่นยำสูงขึ้น
Chatbot และ Virtual Assistant เช่น ChatGPT, Google Bard, Bing AI
Search Engine และ Recommendation System
ทำให้ระบบค้นหาเข้าใจเจตนาของผู้ใช้ได้ดีขึ้น
เพิ่มความแม่นยำในการแนะนำคอนเทนต์
การประมวลผลภาพและวิดีโอ
ใช้ในงาน Vision Transformer (ViT) สำหรับการจำแนกภาพ
การวิเคราะห์วิดีโอเพื่อรักษาความปลอดภัยหรือการตลาด
การแพทย์
วิเคราะห์ข้อมูลทางพันธุกรรมและโครงสร้างโปรตีน (AlphaFold)
ช่วยแพทย์วินิจฉัยโรคจากภาพถ่ายรังสี
ธุรกิจและการตลาด
วิเคราะห์ข้อมูลผู้บริโภค
การสร้างคอนเทนต์อัตโนมัติ
Transformer Model และโมเดลชื่อดังที่พัฒนาต่อยอด
ตั้งแต่ Transformer Model ถูกเผยแพร่ครั้งแรกในปี 2017 โลกของปัญญาประดิษฐ์ก็ได้ก้าวเข้าสู่ยุคใหม่ที่เต็มไปด้วยความก้าวหน้า โมเดลพื้นฐานนี้ได้กลายเป็นแรงบันดาลใจให้เกิดการพัฒนาสถาปัตยกรรมรุ่นลูกจำนวนมาก ซึ่งแต่ละโมเดลต่างก็ถูกออกแบบมาเพื่อตอบโจทย์เฉพาะด้านของงานประมวลผลภาษาธรรมชาติ (NLP), คอมพิวเตอร์วิทัศน์ (Computer Vision) และงานด้านข้อมูลเชิงซับซ้อนอื่น ๆ โดยเฉพาะ โมเดลที่มีชื่อเสียงและถูกใช้อย่างกว้างขวาง ได้แก่:
BERT (Bidirectional Encoder Representations from Transformers)
BERT เปิดตัวโดย Google ในปี 2018 ถือเป็นโมเดลแรกที่สามารถเข้าใจความหมายของคำในประโยคได้ทั้งสองทิศทาง (Bidirectional) ไม่เหมือนโมเดลก่อนหน้า ที่อ่านประโยคเพียงจากซ้ายไปขวา หรือขวาไปซ้าย BERT ใช้กลไก Masked Language Model (MLM) ซึ่งจะปิดบังคำบางคำในประโยค แล้วให้โมเดลทายว่าคำนั้นควรเป็นอะไร วิธีนี้ช่วยให้โมเดลเข้าใจบริบทได้ลึกซึ้งและแม่นยำกว่าเดิม
การใช้งานจริงของ BERT ได้แก่
- การค้นหาข้อมูลใน Google Search ที่มีความแม่นยำมากขึ้น
- การวิเคราะห์ความคิดเห็น (Sentiment Analysis)
- การตอบคำถามอัตโนมัติ (Question Answering)Transformer Model และโมเดลชื่อดังที่พัฒนาต่อยอด
GPT (Generative Pre-trained Transformer)
GPT จาก OpenAI เป็นอีกหนึ่งโมเดลที่สร้างปรากฏการณ์ครั้งใหญ่ จุดเด่นของ GPT คือการเรียนรู้แบบ Generative ซึ่งสามารถ “สร้างข้อความใหม่” ที่เป็นธรรมชาติและต่อเนื่องราวกับมนุษย์เขียน
ตั้งแต่ GPT-2, GPT-3 จนถึง GPT-4 และ GPT-5 โมเดลตระกูลนี้ถูกฝึกด้วยข้อมูลจำนวนมหาศาล ทำให้สามารถเขียนบทความ แปลภาษา แต่งกลอน หรือแม้แต่เขียนโค้ดโปรแกรมได้อย่างน่าทึ่ง
การใช้งานจริงของ GPT ได้แก่
Chatbot อัจฉริยะ เช่น ChatGPT
การสร้างคอนเทนต์ดิจิทัล
การช่วยนักพัฒนาในการเขียนโค้ดและตรวจสอบข้อผิดพลาด
T5 (Text-to-Text Transfer Transformer)
T5 หรือ Text-to-Text Transfer Transformer จาก Google Research เปิดตัวในปี 2019 โดยมีแนวคิดที่แตกต่าง คือ เปลี่ยนทุกปัญหา NLP ให้อยู่ในรูปแบบการแปลงข้อความเป็นข้อความ (Text-to-Text) เช่น
การแปลภาษา = แปลงข้อความจากภาษา A → ภาษา B
การสรุปบทความ = แปลงข้อความยาว → ข้อความสั้น
การตอบคำถาม = แปลงคำถาม → คำตอบ
โมเดลนี้ช่วยให้การประยุกต์ใช้ NLP มีความเป็นหนึ่งเดียว ทำให้นักพัฒนาสามารถใช้โครงสร้างเดียวกันในการแก้หลายปัญหา
การใช้งานจริงของ T5 ได้แก่
การสรุปเนื้อหาอัตโนมัติในเว็บไซต์ข่าว
ระบบแปลภาษาที่มีความยืดหยุ่น
การตอบคำถามในระบบช่วยเหลือผู้ใช้อัตโนมัติ
Vision Transformer (ViT)
แม้ว่า Transformer จะถูกออกแบบมาเพื่อข้อความ แต่ในปี 2020 ทีมวิจัยของ Google ได้พัฒนา Vision Transformer (ViT) ที่นำสถาปัตยกรรม Transformer มาใช้กับข้อมูลภาพโดยตรง
แนวคิดของ ViT คือการ “แบ่งภาพออกเป็นชิ้นเล็ก ๆ (patches)” แล้วป้อนเข้าสู่โมเดลเหมือนเป็น “คำ” จากนั้นใช้กลไก Self-Attention เพื่อทำความเข้าใจโครงสร้างของภาพ
การใช้งานจริงของ ViT ได้แก่
การจดจำวัตถุในภาพถ่าย (Object Detection)
การวิเคราะห์ภาพทางการแพทย์ เช่น ตรวจหาความผิดปกติจากเอกซเรย์
ระบบกล้องวงจรปิดอัจฉริยะในด้านความปลอดภัย
สรุป
Transformer Model คือหนึ่งในนวัตกรรมที่ยิ่งใหญ่ที่สุดของวงการ AI และเทคโนโลยีสารสนเทศ มันได้เปลี่ยนแนวทางการสร้างโมเดลจากเดิมที่ต้องพึ่งพา RNN และ LSTM มาเป็นการใช้ Attention ที่มีประสิทธิภาพสูงกว่า Transformer ไม่เพียงแต่ทำให้คอมพิวเตอร์เข้าใจภาษามนุษย์ได้ดีขึ้น แต่ยังสามารถนำไปประยุกต์ใช้กับงานหลากหลาย ตั้งแต่ธุรกิจ การแพทย์ การศึกษา จนถึงความบันเทิง
หากมองในมิติของ SEO และการสร้างเนื้อหาดิจิทัล การทำความเข้าใจ Transformer Model ยังช่วยให้เราคาดการณ์ทิศทางของ AI ได้ดียิ่งขึ้นว่าอนาคตของอินเทอร์เน็ตและเทคโนโลยีจะเดินไปทางไหน นี่คือเหตุผลที่ทำให้ Transformer Model ไม่ใช่แค่เครื่องมือทางวิชาการ แต่เป็น “หัวใจของนวัตกรรม” ที่กำลังขับเคลื่อนโลกสู่อนาคต





